一、 背景描述
在集群重启了之后,运维人员在测试的时候发现集群进程负载很高,有时候进行ls会有缓慢的情况,并且 我们通过top查看到集群的SNN进程cpu消耗100%
二、 问题定位以及排查方案
查询系统占用CPU100%消耗线程很简单,用top -H -p 命令即可看到每条线程的占用,该线程的线程ID是十进制的

我们通过jstack对SNN的线程栈进行定位,将46274转化为十六进制得到b4c2的线程号,得到当时线程的栈调用,发现当时调用的线程信息,发现这个耗时主要发生在Edit log tailer线程中
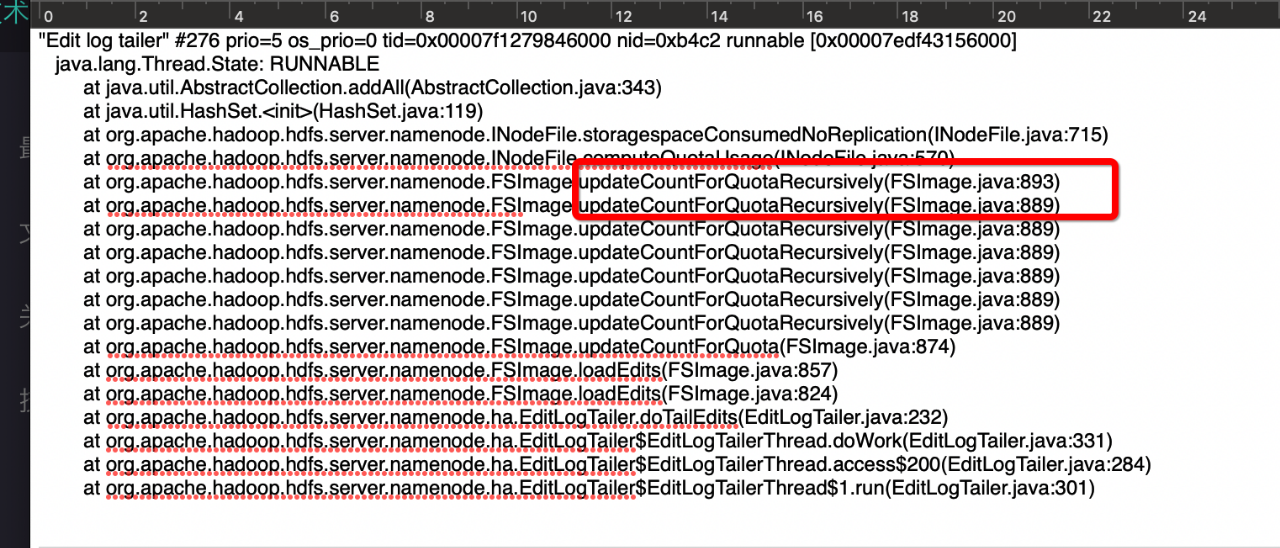
然后我们查看源码,我们每次进行loadEdits的时候,都会进行countforQuota的统计,那么我们知道,NN会定时去加载Edits,那么是多久的时间呢?
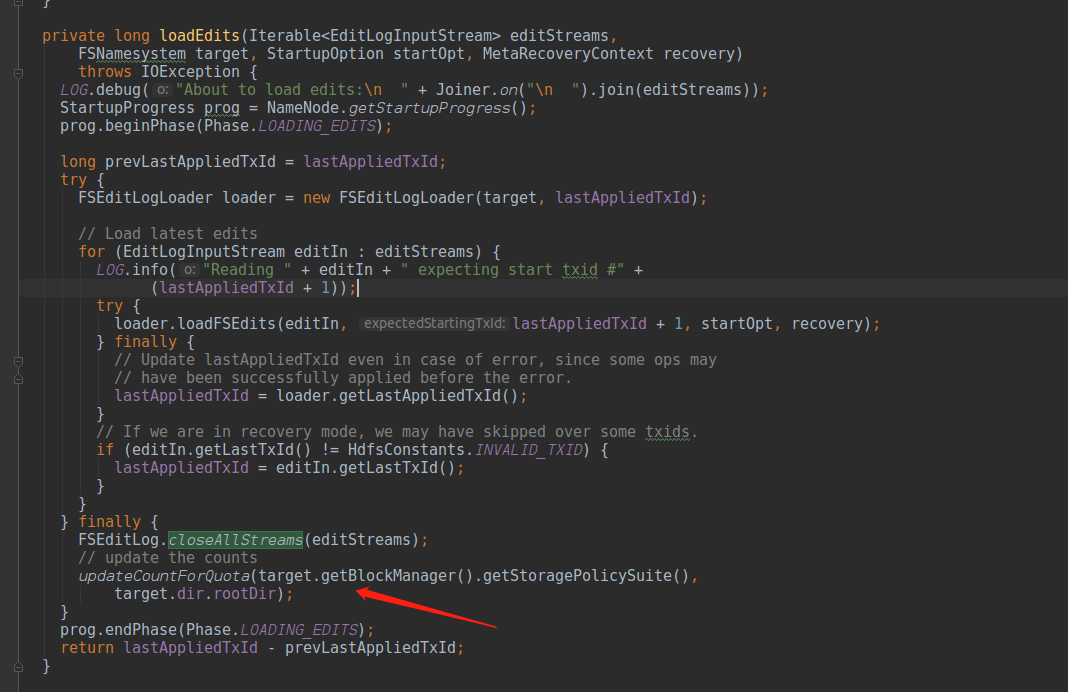
我们查看EditLogTailerThread线程,查看他的时间间隔,知道我们60s执行一次EditlogTailer, 然后做一次updateCountForQuota的操作,会耗费很多时间,那么调优的时候,要么增加一定的时间间隔,降低CPU的消耗,但是会影响loadEdis的及时性,要么优化代码结构,加速计算,那么我们查找下方案
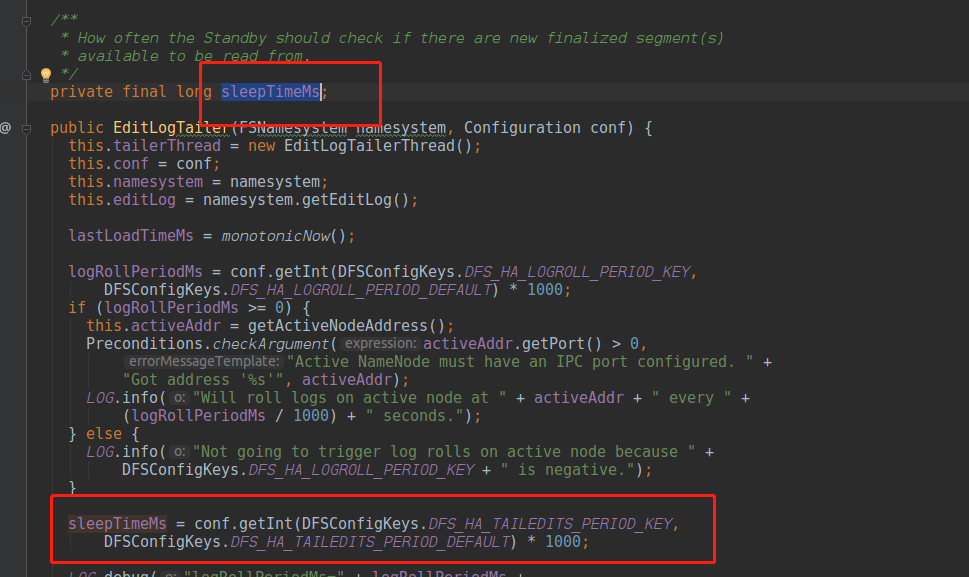
所以经过查找,社区上也有人遇到类似问题,并且有一些相关的patch,这里有一些文章

除了Patch之外,还有HDFS-8865也讨论了类似的问题,HDFS-6763其实是基于HDFS-8865的一个改进版,其核心通过构造InitQuotaTask来加速计算的过程,从而达到优化的效果,详细的学习建议参考ISSUE上面的详细讨论和方案的设计。
参考
https://issues.apache.org/jira/browse/HDFS-8865